内容checklist:
- 第一章:
- 什么是机器学习&用到机器学习的例子
- 机器学习和普通的写代码的区别
- 机器学习的分类&监督学习无监督学习的区别
- 机器学习解决的任务(task)
- feature&target variable的含义
- 机器学习的流程
- python包的安装
- python中numpy的使用(array&mat)
- 第二章:
- kNN的基本原理&步骤
- 用numpy计算欧氏距离(分别算出dataset中每一行和一个数组inX的距离)
- 用numpy的argsort对每个元素排序,理解结果的含义
- 统计每个类别出现的次数
- 用sorted函数的高级用法(key、reverse两个参数)对一个字典按照value排序
- 数据Normalization的方法(减去平均值除以标准差、减去最小值除以数据范围)
- 同时有类别数据和数值数据时的距离计算方式
- 第三章:
- 西瓜书的图解:
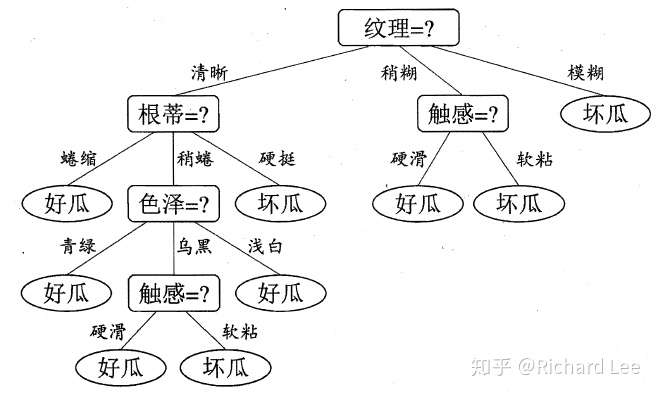
- 决策树(ID3)的基本原理&步骤(伪代码)
- 决策树分叉的含义
- 熵(entropy)、信息增益(information gain)的计算方法
- 决策树选择最好feature的方式
- 决策树结构存储和加载的方式
- 利用存储的决策树进行测试的方式
- 第四章:
- 能举出用贝叶斯公式计算的例子
- 能写出贝叶斯公式
- 能知道贝叶斯的应用场景
- 能知道朴素贝叶斯朴素(naive)在什么地方
- 了解Bag of Words
- 能计算出一个词和句子的向量,并能用numpy实现
- 用log和初始统计不为0的原因
- 了解正则表达式及用正则表达式进行分词的方法
- 第五章:
- 动图:

- sigmoid函数及使用sigmoid函数的原因
- 了解0.5的分界是z=0的超平面
- 导数和梯度的概念
- 梯度上升法的作用对象(w)、工作原理与公式
- 随机梯度上升法的概念、不足与改进
- 对缺失值的处理方法
- 第六章:
- 线性可分时:
- 支持向量机的margin概念与计算公式
- 为什么要margin最大,了解margin最大的数学表示方式
- 支持向量的定义
- 了解为什么可以在公式中去掉min(label*(wx+b))
- 了解有个叫做拉格朗日乘子法对偶问题的方法可以解该问题,并且知道公式中有<x(i),x(j)>项,知道要算出一堆alpha
- 知道可以有slack variables,并且知道存在一个C(具体可见西瓜书)
- 知道有个叫做SMO算法的方法,每次选取两个alpha更新(因为需要
alpha*lable的和为0),固定其他的不变
- 线性不可分时:
- 升维的概念以及作用
- 核函数的概念、作用、输入输出
- 高斯核的定义
- 第七章:
- meta-algorithm / ensemble methods 的含义及作用
- bagging和boosting的含义和区别
- AdaBoost的算法流程、数据权重计算方法、分类器权重计算方法
- AdaBoost例子中单层决策树的原理与算法
- 非均衡分类问题的定义与解决:
- confusion matrix、ROC及分类度量指标(accuracy、precision、recall、AUC)的定义
- cost-sensitive learning的定义与cost-matrix的使用
- 数据抽样方法(undersampling和oversampling)
- 第八章:
- 知道线性回归的“线性”含义
- 懂线性代数矩阵相乘、转置、求逆操作的含义,懂y=Xw中X每一行是一条数据,考虑常数项时可以加一列1
- 能看懂OLS(普通最小二乘)的公式:$\hat{w}=\left(X^{\top} X\right)^{-1} X^{\top} y$
- LWLR(局部加权线性回归)的W含义与形式,能看懂公式,知道k的影响并知道为何太大和太小的k都不好
- Ridge Regression和Lasso Regression与线性回归的区别,知道特征数多于样本数的时候不能用OLS,知道lambda的影响(图8.6)
- 前向逐步回归的思想和流程
- 知道偏差和方差的含义:方差指不同数据集上的区别,知道模型复杂度和偏差方差的关系(图8.8)
- 第九章:
- 知道CART(二元切分,连续型)决策树算法
- 知道存储的树的构成形式
- 知道这里的用于回归的决策树优化目标与整体流程
- 知道代码9.2中的三个退出条件
- 知道剪枝的两种(提前终止、测试误差)并知道后剪枝的流程(代码9.3的流程)
- 知道叶子结点有两种(数字 或者 线性模型Model Tree)
- 第十章:
- k-means方法的流程:
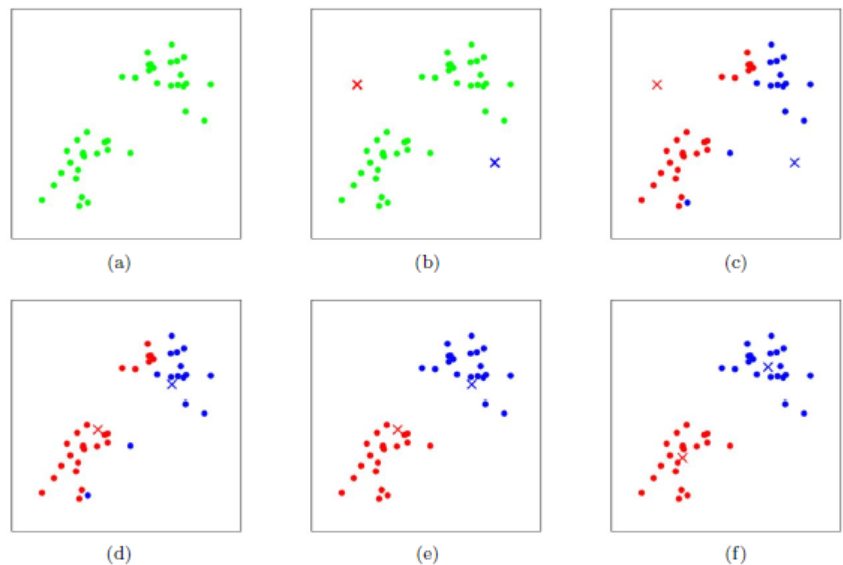
- k-means方法受到随机初始化的影响
- SSE指标
- 二分k-means方法的流程:每次选一个执行2-means
- 第十一章:
- 关联分析的定义:大规模数据集中寻找物品的隐含关系
- support和confidence的定义
- 频繁项集(frequent itemset)的定义
- Apriori算法的数据结构,剪枝(图11.3)
- 关联规则挖掘的剪枝(图11.4)
- Apriori算法的缺点:扫描次数多(每次增大frequent itemset的大小都要扫描一遍数据集)
- 第十二章
- FP-tree的结构(图12.2)
- FP-tree构建过程(表12.2及图12.3)
- 条件FP-tree的构建过程(表12.3及图12.4)
- 第十三章:
- 降维的含义(及开始的球的例子),降维的原因
- 主成分分析(PCA)的原理及方法(方差最大、正交),PCA和特征向量的关系
- 第十四章:
- SVD中分解出来的三个矩阵的形状与含义
- 如何简化数据
- 第十五章:
- 分布式处理数据的MapReduce流程(图15.1)
相关资料:
- 第一章:
- 西瓜书第1章:绪论,第10.1节:k近邻学习
- regression词的来源:155页中间
- 第二章:
- 干货|关于KNN,如果您完全了解算我输…… - cstghitpku的文章 - 知乎
https://zhuanlan.zhihu.com/p/46448216 - KD tree、Ball tree:https://www.cnblogs.com/pinard/p/6061661.html
- 第三章:
- appendix C:Probability refresher
- 西瓜书第4章:决策树
- 第四章:
- 西瓜书第7章:贝叶斯分类器
- 第五章:
- 西瓜书第3.3节:对数几率回归
- 西瓜书附录A.2:导数,B.4:梯度下降法
- appendix B:Linear algebra
- 第六章:
- 西瓜书第6章:支持向量机
- 数学相关:
- appendix B:Linear algebra
- 西瓜书附录B.1:拉格朗日乘子法
- KKT条件的简单解释:浅谈最优化问题的KKT条件 - 力学渣的文章 - 知乎 https://zhuanlan.zhihu.com/p/26514613
- 为什么SVM要用拉格朗日对偶算法来解问题? - 李欣宜的回答 - 知乎 https://www.zhihu.com/question/300015357/answer/519104070
- 拉格朗日对偶问题的一个数学例子:
- 为什么支持向量机要用拉格朗日对偶算法来解最大化间隔问题? - 马同学的回答 - 知乎
https://www.zhihu.com/question/36694952/answer/1616415387
- 为什么支持向量机要用拉格朗日对偶算法来解最大化间隔问题? - 马同学的回答 - 知乎
- SVM的一个快速求解方法(SMO算法) - 拉普拉斯算符的文章 - 知乎
https://zhuanlan.zhihu.com/p/367578887
- 第七章:
- 西瓜书第8章:集成学习
- 西瓜书第2.3节:性能度量、3.6节:类别不平衡问题
- 第八章:
- appendix B:Linear algebra
- 方差与偏差:https://www.jianshu.com/p/5830e16398a7 https://youtu.be/EuBBz3bI-aA
- Ridge Regression:https://www.jianshu.com/p/30639c966235 https://youtu.be/Q81RR3yKn30
- 西瓜书第2.1节:经验误差与过拟合,2.5节:偏差与方差,3.1节、3.2节:线性回归,11.4节:嵌入式选择与L1正则化
- 西瓜书附录B.5:坐标下降法
- 第九章:
- 西瓜书第4.2.3节:基尼系数,4.3节:剪枝处理
- 第十章:
- 西瓜书第9章:聚类
- 第十一章:
- 无
- 第十二章:
- 无
- 第十三章:
- 西瓜书第10.3节:主成分分析
- PCA:https://youtu.be/FgakZw6K1QQ https://www.jianshu.com/p/7d4d278b0e5b
- 第十四章:
- SVD(奇异值分解)的几何理解
https://zhuanlan.zhihu.com/p/368291724 - 推荐系统矩阵分解的直观理解
https://zhuanlan.zhihu.com/p/368171209
- 第十五章:
- 无





